
Когда вы работаете с текстовым файлом в графическом редакторе, то можно увидеть количество вхождений слова, используя статистику, если она предоставляется редактором или, например, нажать Ctrl+F и увидеть количество найденных вхождений.
Иногда нужно выполнить подсчет вхождений слова или символов в файле, используя командую строку. Рассмотрим, как это можно сделать.
Используем grep | wc
Предположим, что у нас есть файл myfile.txt со следующим содержимым:
Файл, который содержит произвольный текст. По содержимому данного файла мы будем искать вхождения слова текст. Слово текст здесь должно встретиться три раза.Воспользуемся командой grep и найдем вхождение слова «текст» в файле myfile.txt:
grep -o -i текс myfile.txt | wc -lВ результате будет выведено:
3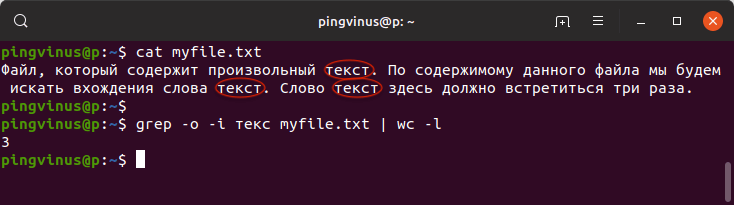
Описание команды:
Команда grep выполняет поиск слова «текст» в файле myfile.txt.
Опция -i — игнорировать регистр символов.
Опция -o — используется, чтобы возвращалось само найденное слово. Каждое найденное слово выводится на отдельной строке (в нашем случае каждое слово передается команде wc).
Далее вывод команды grep направляется команде wc, так как используется оператор вертикальной черты | (конвейер).
Команда wc (от «word count») с опцией -l выполняет подсчет количества строк. То есть в нашем случае количество, найденных командной grep, слов.
Используем tr | grep
Для разнообразия воспользуемся еще одной командой, которая также выполняет подсчет количества вхождений строки в текстовом файле:
tr '[:space:]' '[\n*]' < myfile.txt | grep -i -c текстВ результате будет выведено:
3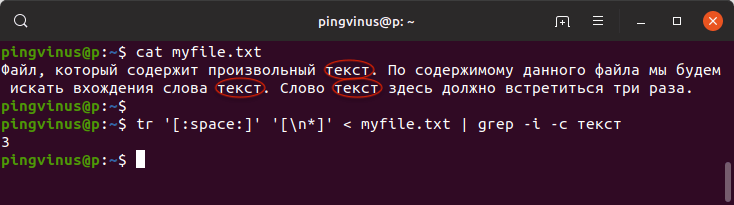
Описание команды:
Мы воспользовались командой tr (от «translate» или «transliterate»), которая используется для преобразования одних символов в другие. В нашем случае мы командной tr разбиваем файл на строки: все пробельные символы ([:space:]) заменяются на символ новой строки ([\n*]).
Затем вывод команды tr направляется команде grep, так как используется конвейер |
Опция -c команды grep считает количество строк.
Еще один пример
Обращаю внимание на то, что описанные выше команды, ищут не отдельное слово, а именно вхождение слова (вхождение символов) в тексте. То есть, если в тексте встречается строка вида «Это хорошие помидоры», и мы ищем вхождение слова «помидор», то получим в результате одно вхождение, так как в нашем тексте есть эти символы.
Приведем пример. Выполним поиск в следующем файле:
Еще один файл, в котором будет выполнен поиск слова пингвинус. При выполнении поиска будут учитываться все вхождения последовательности символов "пингвинус", например, пингвинусу, Пингвинуса, Пингвинус.ру.grep -o -i пингвинус myfile2.txt | wc -lВ результате будет выведено:
5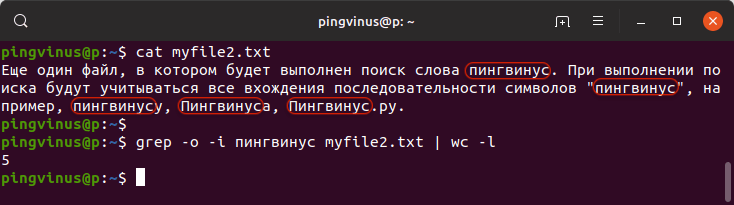
Аналогично командой tr
tr '[:space:]' '[\n*]' < myfile2.txt | grep -i -c пингвинусВ результате будет выведено:
5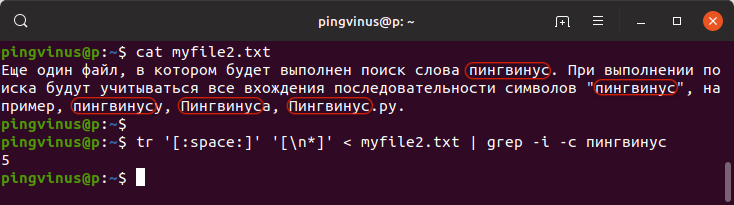
Источник: link
Заключение
Мы рассмотрели, как можно посчитать количество вхождений определенных символов в текстовом файле, используя командую строку. Вы также познакомились с некоторыми возможностями команд grep, wc и tr, и перенаправлением результата одной команды на вход другой — конвейером |
Комментарии
15:00
grep -ico "искомое слово" file_name.txt
15:10
в командном режиме (коммандный режим - shit+; - т.е. шифт + :)
%s/искомое_слово//gn
% - весь файл (а можно указать диапазон строк, т.н. range, 100,254 - начиная с сотой сроки до двухсот пятьдесятчетветой)
s - подстановка (substitute)
/ - разделитель - что ищем и на что заменяем, т.е. ни на что - после второго разделителя пусто
g - global (глобально)
n - none (или что-то иное обозначает, в любом случае это нужное действие, а именно - бездействие, т.е. ничего не удаляет)
16:55
зы Работает и на LibreOffice 6.4 ...
11:18
23:24
grep текст *
В таком случае wc ничего не считает