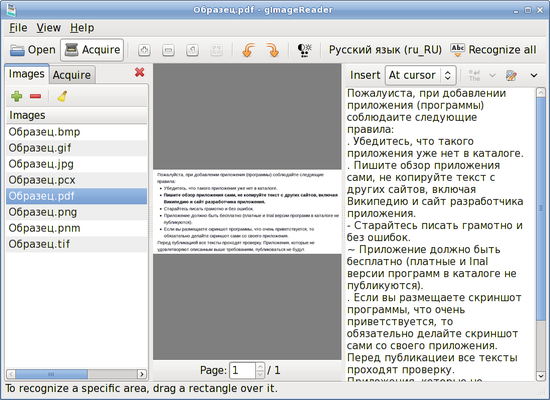
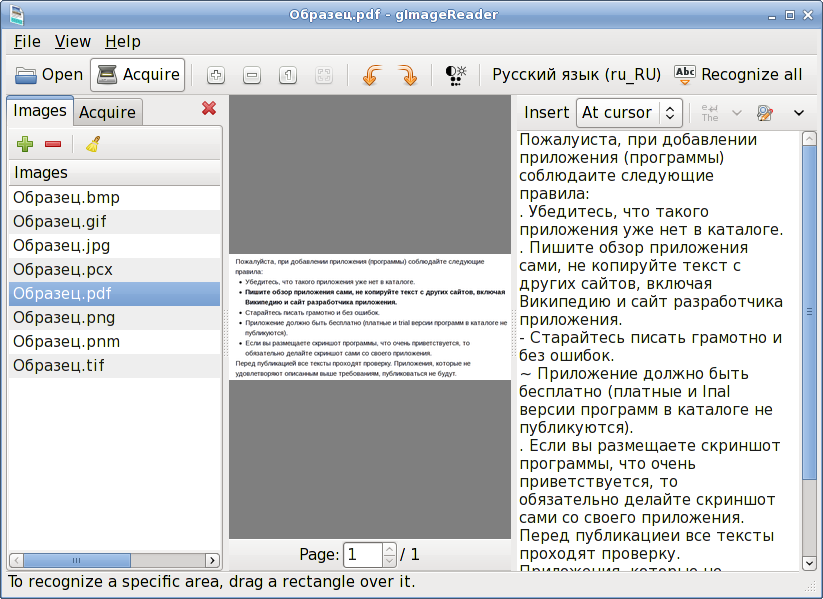
GImageReader — кроссплатформенный графический интерфейс для системы оптического распознавания символов Tesseract. Программа использует графические библиотеки GTK и написана на языке программирования Python. Особенности gImageReader: * Поддерживаемые форматы изображений: jpeg, png, tiff, gif, pnm, pcx, bmp. * Поддержка формата электронных документов PDF. Возможность выбрать отдельные страницы и диапазон страниц для распознавания. * Выделение области с текстом для распознавания. * Получение изображения напрямую со сканера. Настройка разрешения, сохранение в формат png. * Проверка орфографии.
Зависимости: tesseract-ocr, python-gtk (PyGTK), python-cairo (PyCairo), python-poppler (PyPoppler), python-enchant (PyEnchant), python-gtkspell (PyGTKspell), python-imaging (PIL), python-imaging-sane (необязательно, только для сканирования). В свою очередь, Tesseract (начиная с 3-й версии) зависит от пакета LibLeptonica (Leptonica).
Установка * Ubuntu и Debian, Fedora — в репозитории gImageReader есть готовые пакеты. * Slackware — см. инструкцию: http://www.salixos.org/wiki/index.php/Распознавание_текста * Arch — скрипт для сборки PKGBUILD в AUR репозитории: https://aur.archlinux.org/packages.php?K=gimagereader
Установил. Сделал тест - распознать одну страницу PDF формата. Получил какие-то крякозябры. Вдобавок к этому страница очень долго "распознавалась". Причину не подскажете?
В программе предварительно нужно выбрать распознаваемый язык. Зайдите в настройки: меню "File" --> "Configure" --> "Preferred language" --> выберите "Русский язык (ru_RU)" --> кнопка "Применить".
Система Tesseract в настоящее время поддерживает много языков, но только с версии 3. Но третей версии нет в репозиториях "старых" дистрибутивов. Мне пришлось порядком потрудиться, вручную устанавливая нужные библиотеки, чтобы программа распознавала русский (и другой неевропейский) текст из под Ubuntu 10.4. В целом можно отметить медленную работу, к тому же программа чувствительна к качеству изображения. Ещё один минус - распознавание ведётся только на каком-либо одном языке, то есть если в русском тексте присутствуют слова, написанные латинскими буквами, то правильно распознать его сходу будет нельзя. Но в целом, стоит отметить что для начала вполне не плохо, учитывая что направление свободного OCR-софта в среде LINUX только начинает развиваться.
Проверьте в /usr/share/tesseract/tessdata/ наличие файлов, начинающихся на "rus.". Если их нет, то вам нужно установить пакет с дополнительными файлами для распознавания русского языка.
Спасибо за программу, особенно за то, что напмсали про устпновку в Arch linux, очень удобно писать сразу wget "..." и переходить к сборке, делайте так почаще)
Комментарии
20:48
Причину не подскажете?
06:39
06:42
07:01
16:30
06:12
10:17
10:17
19:13
В целом можно отметить медленную работу, к тому же программа чувствительна к качеству изображения. Ещё один минус - распознавание ведётся только на каком-либо одном языке, то есть если в русском тексте присутствуют слова, написанные латинскими буквами, то правильно распознать его сходу будет нельзя.
Но в целом, стоит отметить что для начала вполне не плохо, учитывая что направление свободного OCR-софта в среде LINUX только начинает развиваться.
16:15
10:19
19:55
18:58
20:40
21:35
10:27
после этого:
sudo synaptic в поиске: tesseract-ocr-rus
как -то так
ссылка на скрин: http://itmages.ru/image/view/1915491/4a3b8d2e
там где всякие каракули - написано на латинице
10:44
18:13
gImageReader
sudo add-apt-repository ppa:sandromani/gimagereader
sudo apt-get update
sudo apt-get install gImageReader
Tesseract
sudo apt-get install tesseract-ocr
sudo apt-get install tesseract-ocr-rus (для установки русского языка)
Программа русифицирована) Имхо на данный момент лучшая распознавалка среди свободного софта, гугл плохо не делает)
17:01
15:58