 Расскажу о двух простых способах вывода текстового файла в терминале с отображением номеров строк. Это может быть полезно, например, программистам или тем, кто много работает с конфигурационными файлами, используя терминал в Linux.
Расскажу о двух простых способах вывода текстового файла в терминале с отображением номеров строк. Это может быть полезно, например, программистам или тем, кто много работает с конфигурационными файлами, используя терминал в Linux.
Для теста я буду использовать файл следующего содержания, содержащий 4 строки:
Строка номер один
Строка номер три
Строка номер четыреВторая строка в файле пустая.
Команда nl
В простейшем случае для команды nl необходимо указать имя файла:
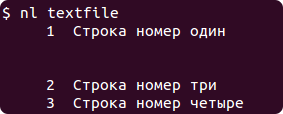
nl textfileВ результате на экран будет выведено содержимое файла, а слева будут стоять номера строк:
$ nl textfile
1 Строка номер один
2 Строка номер три
3 Строка номер четыреОбратите внимание, что пустую строку в файле команда nl проигнорировала. Для того, чтобы учитывались все строки используется ключ -ba:
$ nl -ba textfile
1 Строка номер один
2
3 Строка номер три
4 Строка номер четыреКоманда nl поддерживает различные форматы вывода (стили) и некоторые дополнительные опции. Для получения справки выполните:
man nlКоманда cat с ключом -n
У команды cat есть аргумент -n, который предназначен для вывода файла с нумерацией строк. Выполним:
cat -n textfile
1 Строка номер один
2
3 Строка номер три
4 Строка номер четыре
Мы получили аналог выполнения nl -ba textfile. Для пропуска пустых строк необходимо использовать ключ -b:
cat -b textfile
Комментарии
15:43
22:21
20:13
nl -w1 README.md
выглядит красивее (нумерация идет с минимальным отступом)
12:00
21:41
02:26
grep -n выводит также и содержимое.
12:03
вариант 1:
$ grep -n zebra top-NNN.txt | cut -d: -f1
979
вариант 2:
$ grep -n zebra top-NNN.txt | awk 'BEGIN {FS=":"} {print $1}'
979